
TensorFlow 快速入门
一、安装
我们这里使用 Docker 进行安装,默认本地已经安装了 Docker 环境,其他下载安装方法请参考这篇文章下载与安装TensorFlow。
1、获取镜像
安装带有jupyter notebook的版本
docker pull tensorflow/tensorflow:latest-py3-jupyter2、启动
docker run -it --rm -v /Users/kaiyiwang/Code/ai/notebooks:/tf/notebooks -p 8888:8888 tensorflow/tensorflow:latest-py3-jupyter命令说明:-v /Users/kaiyiwang/Code/ai/notebooks:/tf/notebooks 将本地的 /Users/kaiyiwang/Code/ai/notebooks 文件夹挂载到新建容器的 /tf/notebooks 下(这样创建的文件可以保存到本地 /Users/kaiyiwang/Code/ai/notebooks)。
注意:这里映射容器里的路径必须为 /tf/ 下面的,否则notebooke 打开会找不到对应宿主机的路径。
二、基本使用
TensorFlow 的特点
- 使用图 (graph) 来表示计算任务.
- 在被称之为
会话 (Session)的上下文 (context) 中执行图. - 使用 tensor 表示数据.
- 通过
变量 (Variable)维护状态. - 使用 feed 和 fetch 可以为任意的操作(arbitrary operation) 赋值或者从其中获取数据.
TensorFlow 综述
TensorFlow 是一个编程系统, 使用图来表示计算任务.图中的节点被称之为 op (operation 的缩写). 一个 op 获得 0 个或多个Tensor, 执行计算, 产生 0 个或多个 Tensor. 每个 Tensor 是一个类型化的多维数组. 例如, 你可以将一小组图像集表示为一个四维浮点数数组, 这四个维度分别是[batch, height, width, channels].
一个 TensorFlow 图描述了计算的过程. 为了进行计算, 图必须在
会话里被启动.会话将图的 op 分发到诸如 CPU 或 GPU 之类的 设备 上, 同时提供执行 op 的方法. 这些方法执行后, 将产生的 tensor 返回. 在 Python 语言中, 返回的 tensor 是 numpy ndarray 对象; 在 C 和 C++ 语言中, 返回的 tensor 是tensorflow::Tensor 实例。
TensorFlow 计算图
TensorFlow 程序通常被组织成一个构建阶段和一个执行阶段. 在构建阶段, op 的执行步骤 被描述成一个图. 在执行阶段, 使用会话执行执行图中的 op.
例如, 通常在构建阶段创建一个图来表示和训练神经网络,然后在执行阶段反复执行图中的训练 op.
小试牛刀
import tensorflow as tf
# 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点
# 加到默认图中.
#
# 构造器的返回值代表该常量 op 的返回值.
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量 op, 产生一个 2x1 矩阵.
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.
# 返回值 'product' 代表矩阵乘法的结果.
product = tf.matmul(matrix1, matrix2)默认图现在有三个节点,两个 constant() op, 和一个matmul() op。为了真正进行矩阵相乘运算,并得到矩阵乘法的 结果,你必须在会话里启动这个图。
在一个会话中启动图
构造阶段完成后, 才能启动图。启动图的第一步是创建一个 Session 对象,如果无任何创建参数, 会话构造器将启动默认图。
# 启动默认图.
sess = tf.Session()
# 调用 sess 的 'run()' 方法来执行矩阵乘法 op, 传入 'product' 作为该方法的参数.
# 上面提到, 'product' 代表了矩阵乘法 op 的输出, 传入它是向方法表明, 我们希望取回
# 矩阵乘法 op 的输出.
#
# 整个执行过程是自动化的, 会话负责传递 op 所需的全部输入. op 通常是并发执行的.
#
# 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行.
#
# 返回值 'result' 是一个 numpy `ndarray` 对象.
result = sess.run(product)
print result
# ==> [[ 12.]]
# 任务完成, 关闭会话.
sess.close()Session 对象在使用完后需要关闭以释放资源. 除了显式调用 close 外, 也可以使用 "with" 代码块 来自动完成关闭动作.
with tf.Session() as sess:
result = sess.run([product])
print result变量
变量维护图执行过程中的状态信息.下面的例子演示了如何使用变量实现一个简单的计数器.
# 创建一个变量, 初始化为标量 0.
state = tf.Variable(0, name="counter")
# 创建一个 op, 其作用是使 state 增加 1
one = tf.constant(1)
new_value = tf.add(state, one)
update = tf.assign(state, new_value)
# 启动图后, 变量必须先经过`初始化` (init) op 初始化,
# 首先必须增加一个`初始化` op 到图中.
init_op = tf.initialize_all_variables()
# 启动图, 运行 op
with tf.Session() as sess:
# 运行 'init' op
sess.run(init_op)
# 打印 'state' 的初始值
print sess.run(state)
# 运行 op, 更新 'state', 并打印 'state'
for _ in range(3):
sess.run(update)
print sess.run(state)
# 输出:
# 0
# 1
# 2
# 3
代码中 assign() 操作是图所描绘的表达式的一部分, 正如 add() 操作一样. 所以在调用 run() 执行表达式之前, 它并不会真正执行赋值操作.
通常会将一个统计模型中的参数表示为一组变量.例如, 你可以将一个神经网络的权重作为某个变量存储在一个 tensor 中.在训练过程中, 通过重复运行训练图, 更新这个 tensor.
三、TensorFlow简单应用
这里我们继续通过一些小例子来让大家进一步熟悉tensorflow框架。
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
#import tensorflow as tf
import tensorflow.compat.v1 as tf # 这里使用V1版本
from tensorflow.python.framework import ops
from tf_utils import load_dataset, random_mini_batches, convert_to_one_hot, predict
#tensorflow2 转为 tensorflow1
tf.disable_v2_behavior()
%matplotlib inline
np.random.seed(1)WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/compat/v2_compat.py:65: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term线性函数
下面我们用tensorflow来实现人工智能领域中著名的线性函数: $ Y = WX + b $。学习过我教程中前面文章的同学已经对这个函数特别熟悉了。在本例中,我们设W的维度是(4,3),X的维度是(3,1)以及b的是(4,1)。它们里面填充的都是随机数。
def linear_function():
np.random.seed(1)
X = tf.constant(np.random.randn(3, 1), name = "X") # 定义一个维度是(3, 1)的常量,randn函数会生成随机数
W = tf.constant(np.random.randn(4, 3), name = "W")
b = tf.constant(np.random.randn(4, 1), name = "b")
Y = tf.add(tf.matmul(W, X), b)# tf.matmul函数会执行矩阵运算
# 创建session,然后用run来执行上面定义的操作
sess = tf.Session()
result = sess.run(Y)
sess.close()
return resultprint( "result = " + str(linear_function()))result = [[-2.15657382]
[ 2.95891446]
[-1.08926781]
[-0.84538042]]sigmoid函数
上面我们用tensorflow实现了深度学习中著名的线性函数,下面我们再来实现sigmoid这个著名的非线性函数。其实,tensorflow框架已经帮我们实现了这些函数了,我们只需要学会使用它们就可以了。下面我给大家展示一下如何用placeholder来使用tensorflow中的sigmoid函数。
def sigmoid(z):
x = tf.placeholder(tf.float32, name="x") # 定义一个类型为float32的占位符
sigmoid = tf.sigmoid(x) # 调用tensorflow的sigmoid函数,并且将占位符作为参数传递进去
with tf.Session() as sess: # 创建一个session
# 用run来执行上面定义的sigmoid操作。
# 执行时将外面传入的z填充到占位符x中,也就相当于把z作为参数传入了tensorflow的sigmoid函数中了。
result = sess.run(sigmoid, feed_dict = {x: z})
return resultprint ("sigmoid(0) = " + str(sigmoid(0)))
print ("sigmoid(12) = " + str(sigmoid(12)))sigmoid(0) = 0.5
sigmoid(12) = 0.9999938细心的同学可能发现有两种方法可以创建tensorflow的session:
方法 1:
sess = tf.Session()
result = sess.run(..., feed_dict = {...})
sess.close() 方法 2:
with tf.Session() as sess:
result = sess.run(..., feed_dict = {...})两种方法都可以使用,具体看个人的喜好。
Cost函数
cost函数也是人工智能领域的一个重要部分。像sigmoid一样,tensorflow也已经帮我们定义好了各种著名的cost函数。在前面的教程中,我们需要写不少python代码来实现下面的cost函数,而如果使用tensorflow框架,只需要一行代码就可以了:
$$ J = - \frac{1}{m} \sum_{i = 1}^m \large ( \small y^{(i)} \log a^{ [2] (i)} + (1-y^{(i)})\log (1-a^{ [2] (i)} )\large )\small\tag{2}$$
我们可以用下面的tensorflow函数来一次性实现sigmoid和上面的cost函数,上面的cost函数也叫做cross_entropy函数:
tf.nn.sigmoid_cross_entropy_with_logits(logits = ..., labels = ...)
logits参数就是我们最后一层神经元输出的z,labels就是我们的真实标签y。上面的tensorflow函数同时实现了sigmoid和cost函数,所以等于一次性实现了下面的函数:
$$ - \frac{1}{m} \sum_{i = 1}^m \large ( \small y^{(i)} \log \sigma(z^{[2] (i)}) + (1-y^{(i)})\log (1-\sigma(z^{[2] (i)})\large )\small\tag{2}$$
def cost(z_in, y_in):
z = tf.placeholder(tf.float32, name="z") # 创建占位符
y = tf.placeholder(tf.float32, name="y")
# 使用sigmoid_cross_entropy_with_logits来构建cost操作。
cost = tf.nn.sigmoid_cross_entropy_with_logits(logits=z, labels=y)
# 创建session
sess = tf.Session()
# 将传入的z_in和y_in填充到占位符中,然后执行cost操作
cost = sess.run(cost, feed_dict={z: z_in, y: y_in})
sess.close()
return costlogits = np.array([0.2, 0.4, 0.7, 0.9])
cost = cost(logits, np.array([0, 0, 1, 1]))
print ("cost = " + str(cost))cost = [0.79813886 0.91301525 0.40318605 0.34115386]One Hot编码
再给大家介绍一个tensorflow中很常用的功能——One Hot编码。在人工智能的编程中,我们经常会遇到多分类问题,我们前面学习的softmax就是用来解决多分类问题的。在多分类编程中,我们的y向量要包含0到C-1的数字,里面的C表示类别的数量。例如,假设C是4,那么我们就需要将下图中左边的向量转换成右边的向量。
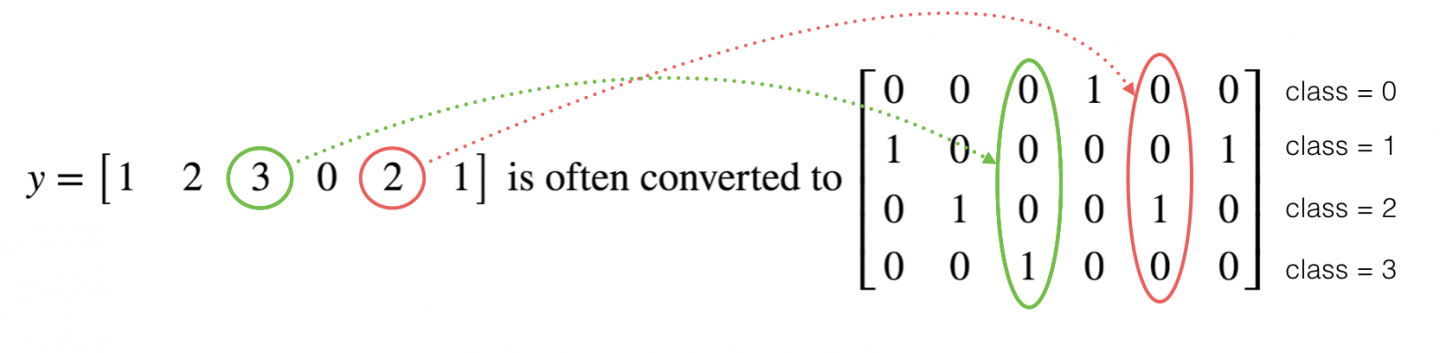
右边的向量就叫做one hot向量,因为向量中只有一个元素是1,其它的都是0。例如,最后一个元素是1就表示类型3。在之前我们实现纯python编程时,如果要实现上面的转换,我们需要写好几行代码,改用tensorflow框架的话,只需要一行代码:
- tf.one_hot(indices, depth, axis)
def one_hot_matrix(labels, C_in):
"""
labels就是真实标签y向量;
C_in就是类别的数量
"""
# 创建一个名为C的tensorflow常量,把它的值设为C_in
C = tf.constant(C_in, name='C')
# 使用one_hot函数构建转换操作,将这个操作命名为one_hot_matrix。
one_hot_matrix = tf.one_hot(indices=labels, depth=C, axis=0)
sess = tf.Session()
# 执行one_hot_matrix操作
one_hot = sess.run(one_hot_matrix)
sess.close()
return one_hotlabels = np.array([1,2,3,0,2,1])
one_hot = one_hot_matrix(labels, C_in=4)
print ("one_hot = " + str(one_hot))one_hot = [[0. 0. 0. 1. 0. 0.]
[1. 0. 0. 0. 0. 1.]
[0. 1. 0. 0. 1. 0.]
[0. 0. 1. 0. 0. 0.]]初始化0和1
最后再介绍两个常用的tensorflow函数,tf.ones()和tf.zeros()。我们将维度信息传入到这两个函数中,它们就会返回填充好1或0的数组。
def ones(shape):
# 将维度信息传入tf.ones中
ones = tf.ones(shape)
sess = tf.Session()
# 执行ones操作
ones = sess.run(ones)
sess.close()
return onesprint ("ones = " + str(ones([3])))ones = [1. 1. 1.]好,tensorflow的基本特性就介绍到这里了,大家应该对tensorflow不再陌生了。
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



